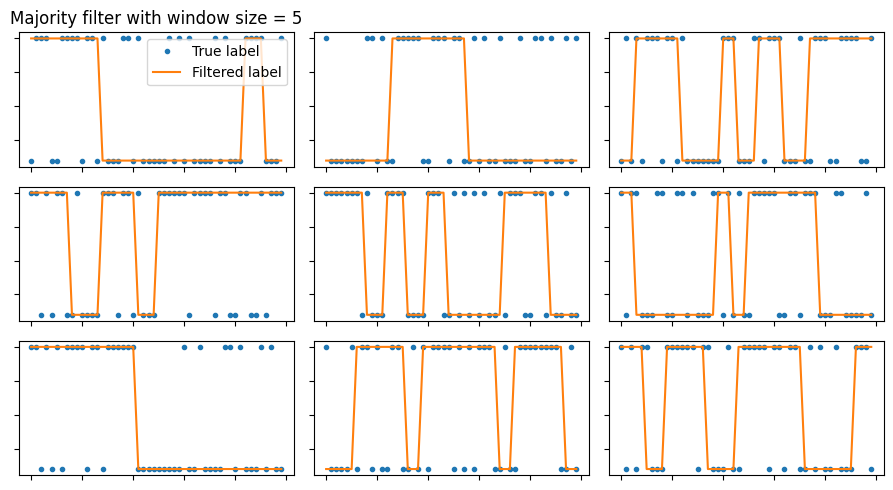
These functions are used to smooth a given vector of labels of heterogeneous processes by means of majority filter. It allows to define a minimum segment length.
Given a vector of changing labels, applies a majority filter to smoothen it. Then, enforces that the minimum segment of a particular label is bigger or equal to the given minimum segment length min_seg.
Type
Default
Details
label
ndarray
Vector to filter by majority vote
window_size
int
5
Size of the window in which the majority filter is applied.
min_seg
int
3
Minimum segment allowed in the output array
Returns
ndarray
Filtered label vector
Example
We create a set of trajectories from models_phenom.multi_state with a high probability of changing states. This makes segments very short. We filter them to ensure that there is not segment smaller than the desired one.
Note that smoothing the signal will have an effect on the actual proportion of time a particle spends in each state. This will be taken into account in the challenge. Here we showcase this effect:
T =100traj, labs = models_phenom().multi_state(N =500, alphas = [[0.7, 1],[0.4,2]], Ds = [[0, 1], [1, 0]], T = T)
We show now the new transition rates (e.g. 1 over the residence time of a given state). Because we are minimum segment length of 3, we can actually approximate the filtered transition rate as the original times 2/3:
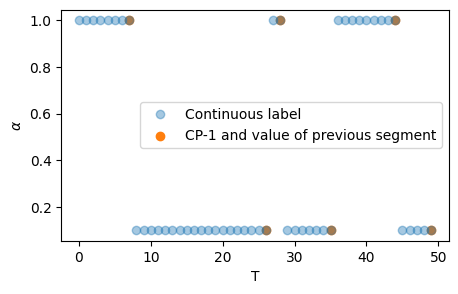
The labels in the challenge will be the list of \(n\) changepoints as well as the \(n+1\) diffusion properties (\(D\) and \(\alpha\)) for each segment. This function transforms the stepwise labels into three lists: CPs, \(\alpha\)s and \(D\)s.
Given an array of T x 2 labels containing the anomalous exponent and diffusion coefficient at each timestep, returns 3 arrays, each containing the changepoints, exponents and coefficient, respectively. If labs is size T x 3, then we consider that diffusive states are given and also return those.
Type
Details
labs
array
T x 2 or T x 3 labels containing the anomalous exponent, diffusion and diffusive state.
Returns
tuple
- First element is the list of change points - The rest are corresponding segment properties (order: alpha, Ds and states)
# Generate the trajectorytrajs, labels = models_phenom().multi_state(N =1, T =50)# Transform the labels:CP, alphas, Ds, _ = label_continuous_to_list(labels[:,-1,:])plt.figure(figsize=(5, 3))plt.plot(labels[:, -1, 1], 'o', alpha =0.4, label ='Continuous label')plt.scatter(CP-1, Ds, c ='C1', label ='CP-1 and value of previous segment')plt.legend(); plt.xlabel('T'); plt.ylabel(r'$\alpha$')
Text(0, 0.5, '$\\alpha$')
List of features to continuous labels
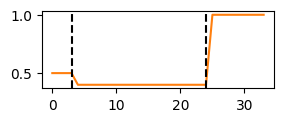
This function does the opposite from than label_continuous_to_list. From a list of properties as the one used in ANDI 2 challenge, creates continuous labels.
Given a list of change points and the labels of the diffusion properties of the resulting segments, generates and array of continuous labels. The last change point indicates the array length.
Type
Details
CP
array, list
list of change points. Last change point indicates label length.
label
array, list
list of segment properties
Returns
array
Continuous label created from the given change points and segment properties
CP = [3,24,34]label = [0.5, 0.4, 1]cont = label_list_to_continuous(CP, label)plt.figure(figsize = (3,1))plt.plot(cont, c ='C1')[plt.axvline(c, c ='k', ls ='--') for c in CP[:-1]];
Given arrays for the position and labels of trajectories, creates a dataframe with that data. The function also applies the demanded FOV. If you don’t want a field of view, chose a FOV length bigger (smaller) that your maximum (minimum) trajectory position.
Type
Default
Details
trajs
array
Trajectories to store in the df (dimension: T x N x 3)
labels
array
Labels to store in the df (dimension: T x N x 3)
min_length
int
10
fov_origin
list
[0, 0]
Bottom left point of the square defining the FOV.
fov_length
float
100.0
Size of the box defining the FOV.
cutoff_length
int
10
Minimum length of a trajectory inside the FOV to be considered in the output dataset.
Returns
tuple
- df_in (dataframe): dataframe with trajectories - df_out (datafram): dataframe with labels
Transform a dataframe as the ones given in the ANDI 2 challenge (i.e. 4 columns: traj_idx, frame, x, y) into a numpy array. To deal with irregular temporal supports, we pad the array whenever the trajectory is not present. The output array has the typical shape of ANDI datasets: TxNx2
Type
Default
Details
df
dataframe
Dataframe with four columns ‘traj_idx’: the trajectory index, ‘frame’ the time frame and ‘x’ and ‘y’ the positions of the particle.
pad
int
-1
Number to use as padding.
Returns
array
Array containing the trajectories from the dataframe, with usual ANDI shape (TxNx2).
Reorganize folder for challenge if non-overlapping FOVS
The outputs of datasets_challenge.challenge_phenom_dataset are not in the appropriate form if one considers the case of non-overlapping FOVS. The latter means that instead of taking n_fovs from the same experiment, we repeat the same experiment n_fovs times. This functions rearranges the folders to get the proper structure proposed in the paper.
This considers that you have n_fovs*n_experiments ‘fake’ experiments and organize them based on the challenge instructions
Type
Default
Details
raw_folder
Path
Original folder with data produced by datasets_challenge.challenge_phenom_dataset
target_folder
Path
Folder where to put reorganized files
experiments
int
Number of experiments
num_fovs
int
Number of FOVS
tracks
list
[1, 2]
Track to consider
save_labels
bool
False
If True, moves all data (also labels,.. etc). Do True only if saving reference / groundtruth data. Moreover, if True also save the trajectories for the video track
task
list
[‘single’, ‘ensemble’]
Which task to consider
print_percentage
bool
True
If True prints, the percentage of states for each experiment
Given an array of trajectories, finds the particles VIP particles that participants will need to characterize in the video trakcl.
The function first finds the particles that exist at frame 0 (i.e. that their first value is different from pad). Then, iterates over this particles to find num_vip that are at distance > than min_distance_part in the first frame.
Type
Default
Details
array_trajs
array
Position of the trajectories that will be considered for the VIP search.
num_vip
int
5
Number of VIP particles to flag.
min_distance_part
int
2
Minimum distance between two VIP particles.
pad
int
-1
Number used to indicate in the temporal support that the particle is outside of the FOV.
boundary
bool
False
If float, defines the length of the box acting as boundary
boundary_origin
tuple
(0, 0)
X and Y coords of the boundary
min_distance_bound
int
0
Minimum distance a particles has to be from the boundary in ordered to be considered a VIP particle
sort_length
bool
True
If True, candidates for VIP particles are choosen in descending trajectory length. This ensures that the longest ones are chosen.
Returns
list
List of indices of the chosen VIP particles
# define random trajectoriesarray_trajs = np.random.rand(200,10, 2)*10# insert paddings to make first trajectories finish earlierpad =-1array_trajs[100, :,:] = padarray_trajs[0,3,0] = padarray_trajs.shape
Given a list of groundtruth and predicted changepoints, solves the assignment problem via the Munkres algorithm (aka Hungarian algorithm) and returns two arrays containing the index of the paired groundtruth and predicted changepoints, respectively.
The distance between change point is the Euclidean distance.
Type
Details
GT
list
List of groundtruth change points.
preds
list
List of predicted change points.
Returns
tuple
- tuple of two arrays, each corresponding to the assigned GT and pred changepoints - Cost matrix
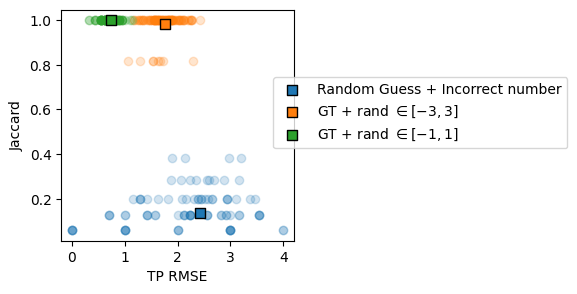
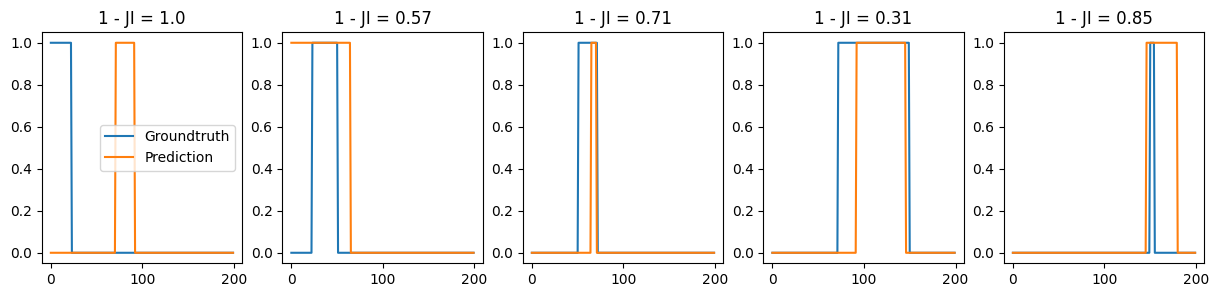
Given the groundtruth and predicted changepoints for a single trajectory, first solves the assignment problem between changepoints, then calculates the RMSE of the true positive pairs and the Jaccard index.
Type
Default
Details
GT
list
List of groundtruth change points.
preds
list
List of predicted change points.
threshold
int
5
Distance from which predictions are considered to have failed. They are then assigned this number.
Returns
tuple
- TP_rmse: root mean square error of the true positive change points. - Jaccard Index of the ensemble predictions
Given an ensemble of groundtruth and predicted change points, iterates over each trajectory’s changepoints. For each, it solves the assignment problem between changepoints. Then, calculates the RMSE of the true positive pairs and the Jaccard index over the ensemble of changepoints (i.e. not the mean of them w.r.t. to the trajectories)
Type
Default
Details
GT_ensemble
list, array
Ensemble of groutruth change points.
pred_ensemble
list
Ensemble of predicted change points.
threshold
int
5
Distance from which predictions are considered to have failed. They are then assigned this number.
Returns
tuple
- TP_rmse: root mean square error of the true positive change points. - Jaccard Index of the ensemble predictions
Here we focus on pairing the segments arising from a list of changepoints. We will use this to latter compare the predicted physical properties for each segment
Given a set of changepoints and the lenght of the trajectory, create segments which are equal to one if the segment takes place at that position and zero otherwise.
Type
Details
CP
list
list of changepoints
T
int
length of the trajectory
Returns
list
list of arrays with value 1 in the temporal support of the current segment.
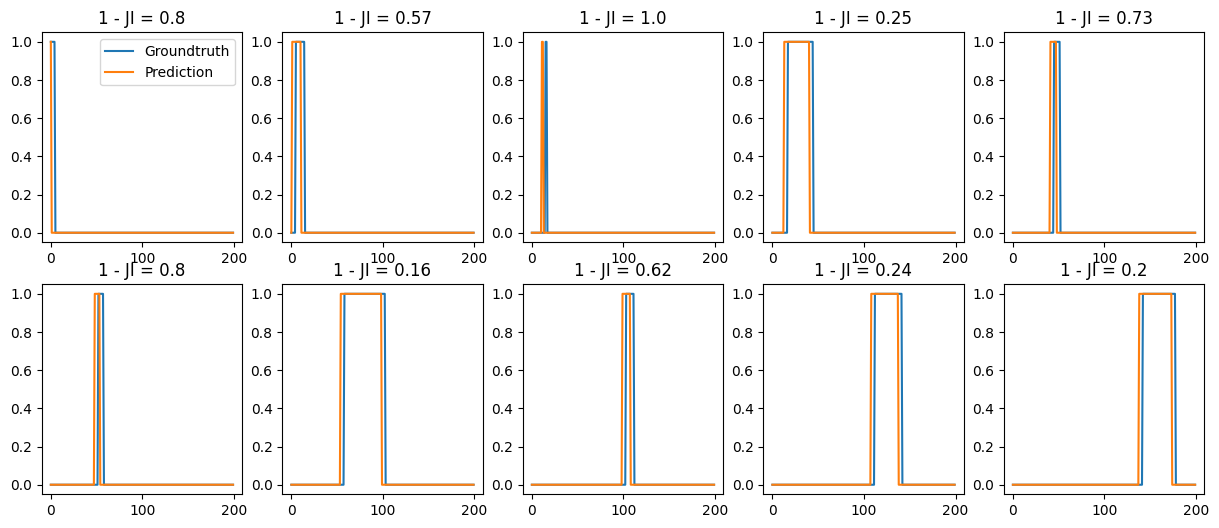
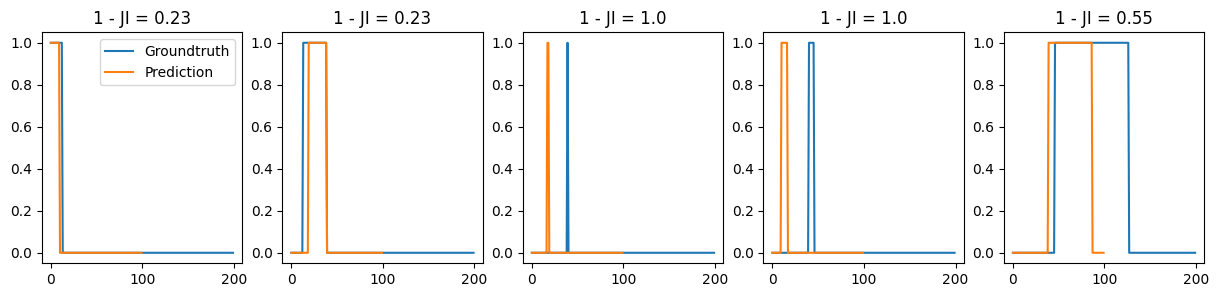
Given a list of groundtruth and predicted changepoints, generates a set of segments. Then constructs a cost matrix by calculting the Jaccard Index between segments. From this cost matrix, we solve the assignment problem via the Munkres algorithm (aka Hungarian algorithm) and returns two arrays containing the index of the groundtruth and predicted segments, respectively.
If T = None, then we consider that GT and preds may have different lenghts. In that case, the end of the segments is the the last CP of each set of CPs.
Type
Default
Details
GT
list
List of groundtruth change points.
preds
list
List of predicted change points.
T
int
None
Length of the trajectory. If None, considers different GT and preds length.
Returns
tuple
- tuple of two arrays, each corresponding to the assigned GT and pred changepoints - Cost matrix calculated via JI of segments
We use the segment pairing functions that we have defined above to compute various metrics between the properties of predicted and groundtruth segments.
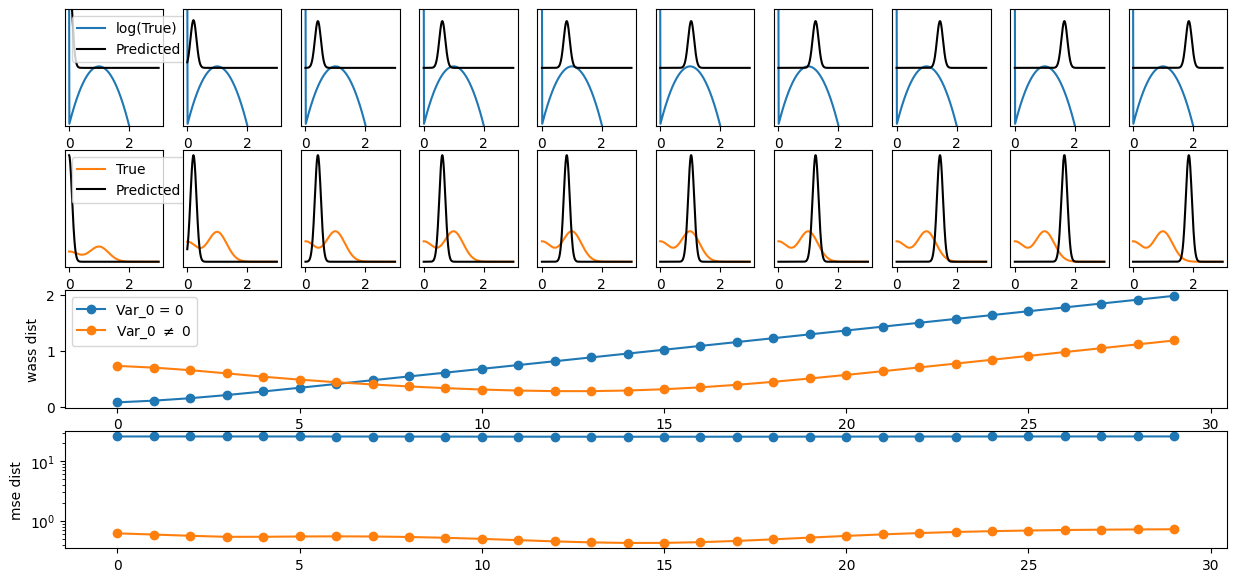
Compute the mean squared log error (msle) between diffusion coefficients. Checks the current bounds of diffusion from models_phenom to calculate the maximum error.
Compute the mean absolute error (mae) between anomalous exponents. Checks the current bounds of anomalous exponents from models_phenom to calculate the maximum error.
Given predicionts over changepoints and variables, checks if in both GT and preds there is an absence of change point. If so, takes that into account to pair variables.
Type
Default
Details
GT_cp
list, int, float
Groundtruth change points
GT_alpha
list, float
Groundtruth anomalous exponent
GT_D
list, float
Groundtruth diffusion coefficient
GT_s
list, float
Groundtruth diffusive state
preds_cp
list, int, float
Predicted change points
preds_alpha
list, float
Predicted anomalous exponent
preds_D
list, float
Predicted diffusion coefficient
preds_s
list, float
Predicted diffusive state
T
bool | int
None
(optional) Length of the trajectories. If none, last change point is length.
Returns
tuple
- False if there are change points. True if there were missing change points. - Next three are either all Nones if change points were detected, or paired exponents, coefficient and states if some change points were missing.
Given predicionts over change points and the value of diffusion parameters in the generated segments, computes the defined metrics.
Type
Default
Details
GT_cp
list, int, float
Groundtruth change points
GT_alpha
list, float
Groundtruth anomalous exponent
GT_D
list, float
Groundtruth diffusion coefficient
GT_s
list, float
Groundtruth diffusive state
preds_cp
list, int, float
Predicted change points
preds_alpha
list, float
Predicted anomalous exponent
preds_D
list, float
Predicted diffusion coefficient
preds_s
list, float
Predicted diffusive state
return_pairs
bool
False
If True, returns the assigment pairs for each diffusive property.
T
NoneType
None
(optional) Length of the trajectories. If none, last change point is length.
Returns
tuple
- if return_pairs = True, returns the assigned pairs of diffusive properties - if return_pairs = False, returns the errors for each diffusive property
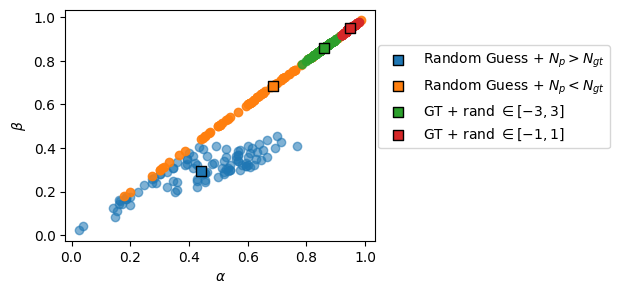
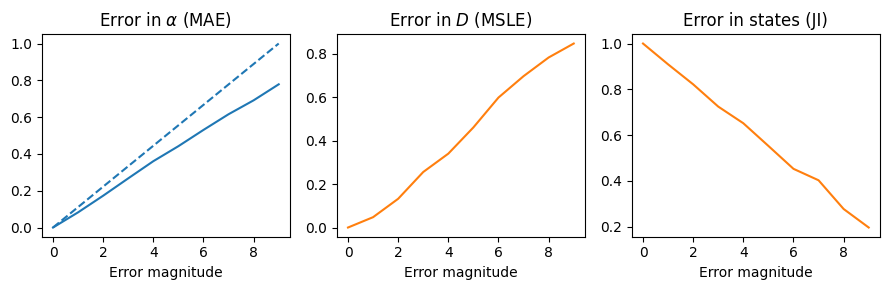
We generate some random predictions to check how the metrics behave. We consider errors also in the change point predictions, hence there will be some segment mismatchings, which will affect the diffusive properties predictions:
fig, ax = plt.subplots(1, 3, figsize = (9, 3), tight_layout =True)ax[0].plot(np.arange(ngts), errors_alpha, c ='C0', ls ='--', label ='Expected with no assigment error')ax[0].plot(np.arange(ngts), metric_a, c ='C0')ax[0].set_title(r'Error in $\alpha$ (MAE)')#ax[1].plot(np.arange(ngts), errors_d, c = 'C1', ls = '--')ax[1].plot(np.arange(ngts), metric_d, c ='C1')ax[1].set_title(r'Error in $D$ (MSLE)')ax[2].plot(np.arange(ngts), metric_s, c ='C1')ax[2].set_title(r'Error in states (JI)')plt.setp(ax, xlabel ='Error magnitude')
fig, ax = plt.subplots(1, 3, figsize = (9, 3), tight_layout =True)ax[0].plot(np.arange(ngts), errors_alpha, c ='C0', ls ='--', label ='Expected with no assigment error')ax[0].plot(np.arange(ngts), metric_a, c ='C0')ax[0].set_title(r'Error in $\alpha$ (MAE)')#ax[1].plot(np.arange(ngts), errors_d, c = 'C1', ls = '--')ax[1].plot(np.arange(ngts), metric_d, c ='C1')ax[1].set_title(r'Error in $D$ (MSLE)')ax[2].plot(np.arange(ngts), metric_s, c ='C1')ax[2].set_title(r'Error in states (JI)')plt.setp(ax, xlabel ='Error magnitude')
Given an array of the diffusive state and a dictionary with the diffusion information, returns a summary of the ensemble properties for the current dataset.
Type
Details
state_label
array
Array containing the diffusive state of the particles in the dataset. For multi-state and dimerization, this must be the number associated to the state (for dimerization, 0 is free, 1 is dimerized). For the rest, we follow the numeration of models_phenom().lab_state.
dic
dict
Dictionary containing the information of the input dataset.
Returns
array
Matrix containing the ensemble information of the input dataset. It has the following shape: |mu_alpha1 mu_alpha2 … | |sigma_alpha1 sigma_alpha2 … | |mu_D1 mu_D1 … | |sigma_D1 sigma_D2 … | |counts_state1 counts_state2 … |
Distance distribution D = 0.06045239400247898
Distance distribution $\alpha$ = 0.10273932574583697
Single trajectory metrics
The participants will have to output predictions in a .txt file were each line corresponds to the predictions of a trajectory. The latter have to be ordered as:
where the first number corresponds to the trajectory index, then d\(_i\), a\(_i\), s\(_i\) correspond to the diffusion coefficient, anomalous exponent and diffusive state of the \(i\)-th segment. For the latter, we have the following code: - 0: immobile - 1: confined - 2: free (unconstrained) - 3: directed
Last, t\(_j\) corresponds to the \(j\)-th changepoints. The last changepoint \(T\) corresponds to the length of the trajectory. Each prediction must contain \(C\) changepoints and \(C\) segments property values. If this is not fulfilled, the whole trajectory is considered as mispredicted.
The .txt file will be first inspected. The data will then be collected into a dataframe
Given a trajectory segments prediction, checks whether it has C changepoints and C+1 segments properties values. As it must also contain the index of the trajectory, this is summarized by being multiple of 4. In some cases, the user needs to also predict the final point of the trajectory. In this case, we will have a residu of 1.
Given two dataframes, corresponding to the predictions and true labels of a set of trajectories from the ANDI 2 challenge022, calculates the corresponding metrics Columns must be for both (no order needed): traj_idx | alphas | Ds | changepoints | states df_true must also contain a column ‘T’.
Type
Default
Details
df_pred
dataframe
Predictions
df_true
dataframe
Groundtruth
threshold_error_alpha
NoneType
None
(same for D, s, cp) Maximum possible error allowed. If bigger, it is substituted by this error.
max_val_alpha
int
2
(same for D, s, cp) Maximum value of the parameter.
min_val_alpha
int
0
(same for D, s, cp) Minimum value of the parameter.
threshold_error_D
NoneType
None
max_val_D
float
1000000.0
min_val_D
float
1e-06
threshold_error_s
NoneType
None
threshold_cp
NoneType
None
prints
bool
True
disable_tqdm
bool
False
If True, disables the progress bar.
Returns
tuple
- rmse_CP: root mean squared error change points - JI: Jaccard index change points - error_alpha: mean absolute error anomalous exponents - error_D: mean square log error diffusion coefficients - error_s: Jaccar index diffusive states
Test
Two datasets with same number of trajs
trajs, labels = models_phenom().immobile_traps(T =200, N =250, alphas=0.5, Ds =1, L =20, Nt =100, Pb =1, Pu =0.5)trajs = trajs.transpose((1, 0, 2)).copy()labels = labels.transpose(1, 0, 2)df_in, df_trues = array_to_df(trajs, labels)trajs, labels = models_phenom().immobile_traps(T =200, N =250, alphas=[0.5, 0.1], Ds =1, L =20, Nt =100, Pb =1, Pu =0.5)trajs = trajs.transpose((1, 0, 2)).copy()labels = labels.transpose(1, 0, 2)df_in, df_preds = array_to_df(trajs, labels)
error_SingleTraj_dataset(df_preds, df_trues, prints =True, disable_tqdm=True);
Due to the restrictions of Codalab, which enforces the inputs / outputs of the scoring programs, it is harder to exactly choose the files we want to process, as well as where we want to put the outputs. Also, we want a function that is able to return the scores in different formats. This function does that.
Local version of codalab_scoring, allowing for custom savings and without df swapping. Labelling is as: Track 1: videos, 2: trajectories; Task 1: Single, 2: Ensemble
Type
Default
Details
submit_dir
directory to where to find the predicted labels (i.e. folder containing folders track_1 and/or track_2)
truth_dir
directory to where to find the reference labels (i.e. folder containing folders track_1 and track_2)
output_dir
directory where the scores will be saved
scores_filename
str
scores.txt
name of the txt scores file
html_filename
str
scores.html
name of the html scores file
dfs_suffix
NoneType
None
if str, suffix of the df filename: df_task_{1|2}track{1|2}_{dfs_suffix}.csv
Helper to transform results dataset in reference dataset
Transforms an organized reference dataset into a valid submission dataset. Note that we do not account for VIP indices in track_1, so will later yield an error when scoring this track.